You can find the live version of my chat bot app here.
A couple months ago, I was watching Matt Souza's show on the CrossFit Network. He was recapping the recent affiliate gathering — mostly focused on the messy private equity sale and what it signaled about leadership.
But the part that stuck with me had nothing to do with that.
To summarize, Don said that offering "free downloadable PDFs on the website" about fitness was really revolutionary back when CrossFit started. However, now, they are finding it hard to bring about the journal's revival so that it falls in line with current technological trends. Souza’s take was simple — and honestly, the most sensible: “make an AI out of it.” He then goes ahead and describes more or less what retrieval augmented generation is and how it could be built using CF Journal articles.
My take: the journal doesn’t need a revival — it never really died. Sure, new articles aren’t being published on the original site. But CrossFit is still producing the same ideas in newer formats: podcasts, videos, and summaries. In many ways, the journal already lives on in CrossFit Essentials — a mix of classic articles and modern content digests.
Naturally, I went for the low-hanging fruit and built the chatbot. This project fits perfectly with this site: CrossFit + machine learning. I’d done a small RAG project a couple years ago (and got the job, by the way), but hadn’t touched it since. It was interesting to come back and see how much the ecosystem — especially tools like LangChain — has evolved.
Source and Scope: The CrossFit Journal
The CrossFit Journal is an extensive digital archive of articles, videos, and technical papers documenting the methodology, training techniques, and nutritional principles of CrossFit. The first article, "What is Fitness?", came out in 2002 and revolutionized the way we define fitness as "measurable, observable, and repeatable" - sound familiar?. I thought at first that I was going to have to parse a bunch of old PDF files, but I really lucked out - everything was accessible through the journal's API in HTML format used for the website.
After a little bit of exploratory data analysis, I decided to narrow the scope for the minimal viable product (MVP) down from the entire library of articles. CrossFit is a world-wide phenomenon and thus there are many articles written in many languages. I am only fluent in English, so in terms of building and testing, it makes sense to limit the corpus to that language. The vast majority of articles are in English and many of the non-English articles were translations, not novel articles. There was a language tag provided in the metadata; however, it didn't catch everything. I ended up using language detection software to doubly-confirm that the articles were in English. Finally, I only included articles longer than 500 words.
CrossFit has two scopes - a fitness methodology designed for all athletes as well as the sport of fitness. There are articles in the journal regarding both; however, I felt like that might be too much for an MVP to include both. I figure the target audience is people who are curious about improving their own fitness or that of others, so I decided to drop all articles related to games content. I was able to do this using article tags like "games", or "fittest on earth", etc. It was also a good call in order to drop a lot of noise from the model as the two can be contradictory at times. For example, the methodology notes that the full range of motion required for a GHD sit up is for the torso to extend down to parallel with the floor. However, in CrossFit competitions, a standard repetition requires the athlete to extend well beyond that and touch hands to floor as it makes the movement easier to judge for completion.
Finally, I limited the scope to text-based data. There are plenty of videos and photos that could be useful to add, but they add much more complexity to the problem and are not necessary for an MVP.
Building the RAG database
Retrieval-Augmented Generation (RAG) improves LLM accuracy by pulling in external data before generating a response — think of it as an open-book exam. Instead of relying purely on what the model “knows,” it retrieves relevant documents and uses them as context. This reduces hallucinations and makes answers traceable. To make this work, we need a searchable database of documents.
I used LangChain to split each article into smaller chunks (based on HTML structure like section headings). Each chunk keeps its metadata for citation purposes. These chunks are then converted into embeddings — numerical vectors that represent the meaning of the text. When a user submits a query, it’s embedded the same way. We then compare vectors (via cosine similarity or dot product) to find the most relevant chunks. The model uses those chunks as context to generate its response. I store everything in BigQuery and use Vertex AI with Gemini models for retrieval and generation.
Two-model “router + answer” pattern
The app uses Gemini models twice per turn:
- Router (structured JSON out): A lightweight model looks at the user message (and a bit of chat history) and decides how to fetch content:
- Metadata route: filter by year, author, tags, title, etc.
- Vector route: pure semantic similarity.
-
Hybrid: narrow the corpus with metadata, then vector search inside that set—handy for, e.g., “2009 articles about nutrition.”
-
Answer: A second call gets the retrieved chunks as CONTEXT in the prompt, with instructions to cite chunk numbers like
[1],[2]and not invent facts. For speed in production, the app can prefer a lighter model and cap history/output length.
So: one model plans the database query; another writes the user-facing reply grounded on what came back.
Ship it
The app is built with FastAPI: Jinja for the UI, cookie-backed sessions, and a JSON API for messaging. It’s containerized with Docker and deployed on Cloud Run, so the same image runs locally and in production.
Room for improvement
The next step is adding video content — not directly, but via transcripts. I looked into this and it would cost roughly $60–100 to transcribe everything. That’s reasonable, but not a priority yet given how much we can still improve using existing data.
Along those same lines, we could potentially expand the knowledge library beyond the Journal. What I love about the CrossFit methodology is that it’s effectively open source. Yes, it's true that in order to officially call yourself a CrossFit coach and coach "CrossFit" classes by name, you need to take the expensive L1 course (worth it, by the way). However, any person can access all of the materials for the L1 and L2 courses at any time for free. There are PDFs available in just about every language imaginable. I could add that content as well. Parsing PDFs is a little more nuanced than raw HTML, but I have done it before. Several journal articles are included in the text of both manuals, so to avoid duplication, I'd need to consider adding cross-references between media sources for shared content.
Similarly, we could expand the corpus to include the newer version of the journal, CrossFit Essentials as well as CrossFit's YouTube channel, which has many video podcasts related to fitness education. We could take advantage of the YouTube API and extract the transcript via the auto-captioning done on every video. This would also be a challenge as well as there is a lot of non-educational content, games content, news, non-instructional workout videos, etc. that we would have to filter out. There's enough content for the YouTube channel to stand alone as its own testament to the CrossFit methodology.
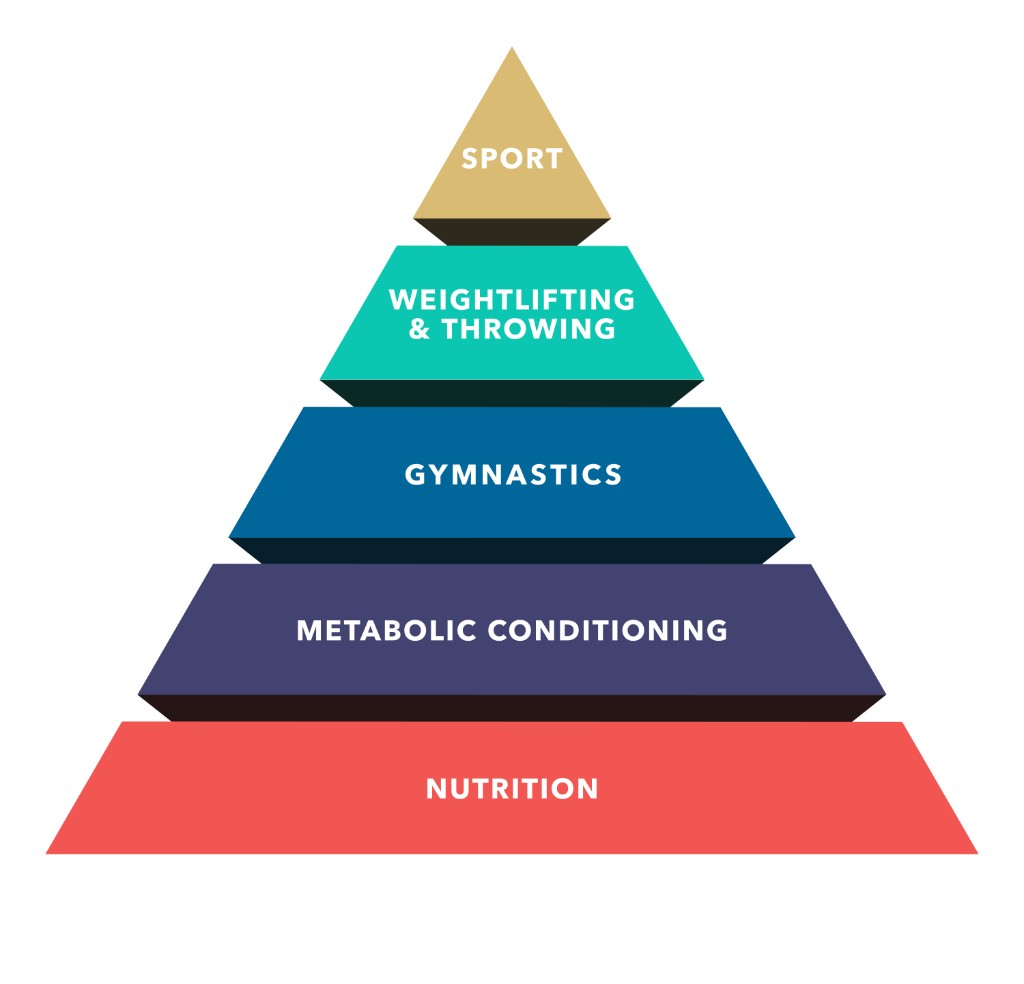
Images would be cool to add as well. Like the videos, we would not directly be inserting images into the vector database. The preprocessing step would be to take in any existing metadata (image url, captions, parent article, etc.) and potentially combine it with an AI-generated description of the image. Imagine asking the chat "how can I improve my fitness?" and it directly inserts the famous pyramid diagram showing CrossFit's hierarchy of fitness development along with a link to the article that describes it in further detail.
The routing system is still pretty basic. Right now, I use predefined functions to translate user input into metadata filters (topics, dates, authors, etc.). A more advanced approach would let the LLM generate queries directly from the database schema — enabling more complex tasks like aggregations. For example, it can answer: “When was 'What is Fitness?' published?” But it struggles with: “What was the first article ever published?” That requires finding the minimum date first — something it doesn’t yet handle well. I’m aware of the limitation, but it’s not critical for an MVP. This tool is meant to teach fitness — not serve as a historical archive.
Go Play
Please feel free to test out my app. I'd be grateful for any feedback you could provide. Please reach out to me via email at traci@crossvalidatedfitness.com. It would be helpful if you could describe the problem and roughly when it occurred (date and time). All chats are logged anonymously for debugging and development — your personal data is not stored.
Apps like this cost money, so while I'm making it free to users, I have set rate limits to prevent runaway costs on my end. So just keep that in mind in case the app slows or kicks you off. I'd be happy to hear from you if that happens, as it means people are engaging with the app!
Private, for now
For now, I’m keeping the repository private. If this project grows beyond the site, I want to maintain control over the IP. That said, I’m still sharing everything I can: data sources, scope, architecture, and design decisions — just not the code itself.